Troubleshooting
opkg commands fail
It could be one of the following causes:
Cause 1: The eManager is not connected to the Internet.
Solution 1: Connect the eManager to a Router/WiFi through a Ethernet cable.
Cause 2: eManager has weak Internet connection.
Solution 2: We recommend upgrading the eManager packages using the perform-opkg-upgrade tool.
Node-RED gets stucked
Node-RED is unreachable or the service is restarting all the time.
Cause 1: it is possible that the flow contains some troublesome node that makes Node-RED to get stucked.
Solution 1: use the console to edit active Node-RED flows.
-
Edit the
flows.jsonfile.Node-RED active flows are stored as a
.jsonfile in/var/lib/node-red/flows.json. You can edit it with: -
After editing the flow, restart the service with:
Cause 2: The npm package manager has been updated without the use of opkg.
Check the eManager npm version with
Depending on the eManager image release the expected npm version is
| Image release | Distro | npm version |
|---|---|---|
| 21.02 | 1.1 | 6.13.4 |
| 21.08 | 1.2 | 6.13.4 |
| 22.01 | 2.0 | 6.14.15 |
| 22.10 | 2.1 | 6.14.15 |
| 24.04 | 3.0 | 10.2.4 |
| 24.10 | 3.1 | 10.2.4 |
| 25.09 | 3.2 | 10.2.4 |
Solution 2: Reinstall the expected version with
I cannot access to the NodeRED application
It could be one of the following causes:
Cause 1: Wrong configuration in the Node-RED flow, which causes the Node-RED to crash.
Solution: Execute the following command in order to check the logs for the error causing the crash:
Cause 2: Node-RED watchdog timeout is too low. It could happen if many components have been installed on the Node-RED palette, causing it to take a long time to load, until the Node-RED watchdog ends up restarting the service.

Solution 2: Execute the following steps in order to change the time of actuation of the watchdog:
-
Access the file
/lib/systemd/system/node-red.service. -
Modify the parameter
WatchdogSecwith the desired time of actuation of the watchdog. -
Execute the following commands to reload the systemd daemon and restart the Node-RED service:
For further information about the watchdog, please check here.
Cause 3: There is some process that monopolizes the CPU.
Solution 3: Review the processes that are running using the top command in the shell.
Sometimes Node-RED restarts for no reason
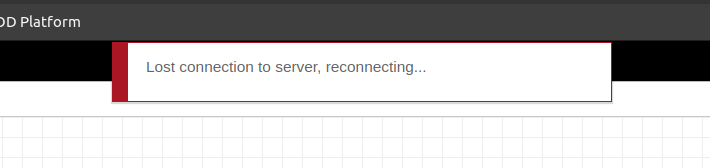
Cause: Node-RED stucked due to incorrect configuration or programming in the Node-RED flow.
Solution: Execute the following command in order to know what is actually causing this:
gyp ERR! stack Error: not found: make
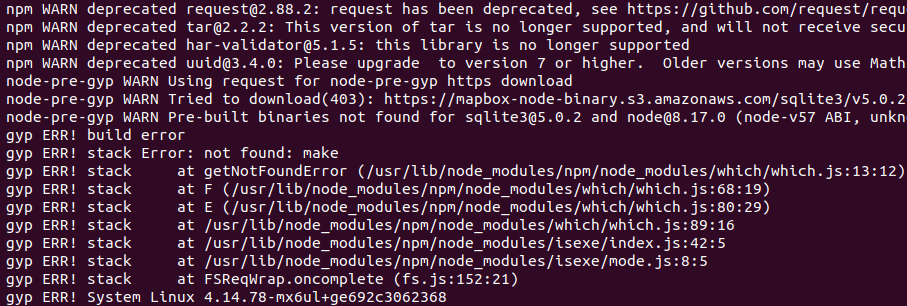
Cause: Some Node-RED packages require the native compiler in the eManager, such as node-red-node-sqlite.
Solution: Install native compiler package:
Finally, restart the node-red service and try again to install the node in Node-RED:
TypeError accessing to a hardware module

Common error messages are:
- Error getting analog input...
- Error getting digital input...
- Error activating relays...
Cause: More than one hardware module request message ocurred at a time, and therefore a collision has occurred.
Collisions can occur when at the same time, on the one hand, a request is made to a hardware module, while another module generates an event from an input.
Solution: If possible, decrease the frequency of polling requests, to minimize collisions.
npm ERR! code EAI_AGAIN
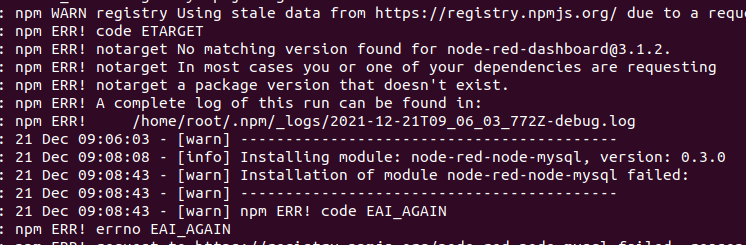
Cause: The Node-RED community has released newer versions of certain nodes that are incompatible with the version of Node-RED used in the eManager. If you attempt to install a package with a version higher than what is supported, this error will occur.
Solution: Manually, install the packet with the last version compatible with the Node-RED version the eManager incorporates. To do so you need to execute the following commands:
For example, we'll assume that node-red-dashboard@3.6.5 is the last compatible version of the node module. To reinstall the previous version <node_red_node_name> is node-red-dashboard and the <version> is <3.6.5>.
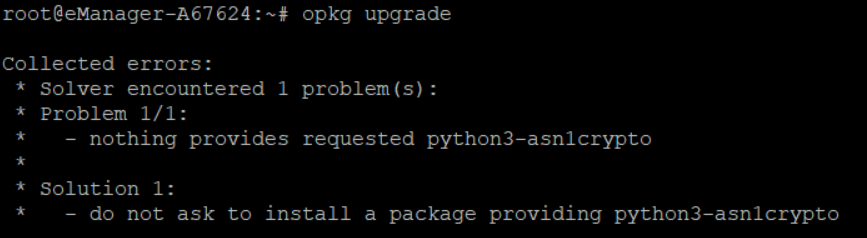
Nothing provides requested <package_name>
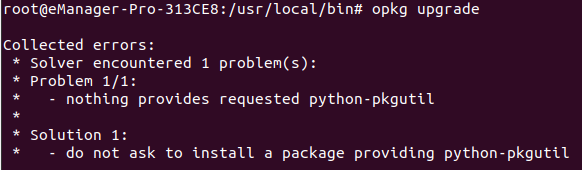
Cause: If you try to install a specific package and the Internet connection is broken during this process, it could happen that some parts of the package are already installed while others are not. In this case, an error similar to the one shown in the image may appear.
Solution: Clean the files cache using:
And reinstall the package using:
In this example <package_name> is python-pkgutil.
Lack of Internet connection when Wi-Fi is working
Cause: The eManager can be connected to Internet via an Ethernet cable and via Wi-Fi. By default, it prioritizes Ethernet, that is, auto-generated Internet routes through the Ethernet interface will take preference over those through the Wi-Fi interface.
Solution: You can manage your Internet connection preferences through Webadmin as explained here.
Opkg database is corrupted
Cause: Some package in the opkg database has experimented a problem during its installation. That makes no longer possible the installation and uninstallation of other packages in your eManager.
Solution: It is necessary to verify if you opkg database is corrupted. To do so:
- Check for duplicated entries:
$ grep "Package: " /usr/lib/opkg/status | sort | wc
$ grep "Package: " /usr/lib/opkg/status | sort -u | wc
- Check that all packages
pfor which a file/usr/lib/opkg/info/$p.listexists is listed in/usr/lib/opkg/status:
for i in /usr/lib/opkg/info/*.list; do
p=$(echo $i | sed -e 's,.*/,,' -e 's,\..*,,')
grep "Package: $p" /usr/lib/opkg/status > /dev/null || echo opkg install $p
done
If no output is displayed, your opkg database is working properly.
If one of the above tests indicates that your opkg database is corrupted:
-
Remove from
/var/lib/opkg/statusthe package entry that causes the error. The package entries follow this structure:2. Install the package that causes the error. In this case, execute:Package: python3-stringold Version: 3.8.11-r0.0 Depends: python3-core Status: install ok installed Architecture: cortexa7t2hf-neon Installed-Size: 31329 Installed-Time: 1666597826 Auto-Installed: yesopkg install python3-asn1crypto --force-reinstall.
Modem disconnects from peer without any apparent cause
You will identify this situation by checking the ppp logs. The following log appears:
Tip
To check the logs use journalctl -f -u ppp@provider -n 100.
Cause: The available channel bandwidth (depending on coverage, environmental conditions, etc.) is very thin, leaving little space for the control messages of the ppp protocol itself.
Solution: Increase the following parameters in /etc/ppp/options-mobile file:
-
lcp-echo-interval: pppd will send an LCP echo-request frame to the peer every n seconds. Normally the peer should respond to the echo-request by sending an echo-reply. This option can be used with the lcp-echo-failure option to detect that the peer is no longer connected. Allowed range: 1 to 255 seconds. The default value is 5 seconds. -
lcp-echo-failure: pppd will presume the peer to be dead if n LCP echo-requests are sent without receiving a valid LCP echo-reply.
We recommend to increase lcp-echo-interval from 10 to 30, and lcp-echo-failure from 3 to 5.
For more information regarding pppd, please check here.
npm could not install a Node-RED node due to network problems
You will identify this situation by the response obtained when installing through commands a Node-RED node. The following should appear:
root@eManager-Pro-5D8F8C:/var/lib/node-red# npm install node-red-dashboard@3.6.5
npm ERR! code ETIMEDOUT
npm ERR! syscall read
npm ERR! errno -110
npm ERR! network read ETIMEDOUT
npm ERR! network This is a problem related to network connectivity.
npm ERR! network In most cases you are behind a proxy or have bad network settings.
npm ERR! network
npm ERR! network If you are behind a proxy, please make sure that the
npm ERR! network 'proxy' config is set properly. See: 'npm help config'
npm ERR! A complete log of this run can be found in: /home/root/.npm/_logs/2024-10-24T10_17_18_445Z-debug-0.log
Cause: A firewall is causing this network problems which makes impossible to install a Node-RED node using npm. You can verify your network connectivity by using the following command:
Solution: You will need to open some ports for npm to be able to use it properly.